Spätestens seit der Veröffentlichung von ChatGPT Ende 2022 ist künstliche Intelligenz (engl. artificial intelligence, kurz AI) in aller Munde und auch in unserem Alltag voll angekommen. Man sollte sich aber bei jedem neuen Werkzeug über dessen Fähigkeiten, Grenzen und Limitierungen bewusst sein und auch AI ist nicht das allumfassende Allheilmittel als das es gerne versprochen wird. Bedacht und klug eingesetzt, ist es ein mächtiges Werkzeug, welches mit umfassendem Wissen über die Welt ausgestattet ist und auf die Eingaben des Nutzers dynamisch eingehen kann.
Zufällig stand bei uns im November wieder ein Hackathon an und was gibt es besseres, um die Grenzen des Sinnvollen auszutesten, als zwei Tage völliger Freiheit von so nervigen externen Zwängen wie Qualitätsanspruch oder Seriosität?
Für unser präferiertes CMS Statamic existieren bereits einige AI Integrationen, um Übersetzungen zu generieren, oder auch Unterstützung bei der Generierung und Anpassung von Texten zu bieten. Aber dies ging uns natürlich nicht weit genug. Ziel für den Hackathon: Wir bauen eine AI Integration, welche dem Verfasser der Texte einer Webseite maximal viel Arbeit abnimmt. Idealerweise gibt man einfach nur ein grobes Thema vor und die AI macht den gesamten Rest. (Unseren Kunden würden wir von solch einer Vorgehensweise abraten, aber für das schnelle Erstellen von realistischen Platzhaltertexten während der Entwicklung ist es sicherlich ein sinnvolles Tool).
Nach einiger Überlegung, was denn unser Output des Hackathons werden soll, fiel die Wahl auf den Webauftritt eines fiktiven Zoos. Insbesondere bei den Tieren gibt es eine Vielfalt an Datenstrukturen, an denen wir die Fähigkeiten der AI austesten können.
Anbindung des Large Language Models
Nach einigem Herumexperimentieren mit verschiedenen Large Language Models (kurz LLM) war klar, dass wir idealerweise verschiedene LLMs anbinden können wollen und sowohl Texte als auch Bilder generieren können möchten. Schnell fiel die Wahl auf Prism, ein Laravel Paket für das nahtlose Einbinden von verschiedensten LLM Providern von OpenAIs GPT, über Googles Gemini, Anthropics Claude zum europäischen Anbieter Mistral. So haben wir die maximale Flexibilität, um Vor- und Nachteile verschiedener LLMs auszuloten und flexibel wechseln zu können.
Die Werkzeuge waren startklar und es stellte sich die Frage, wie genau die Funktionalität aussehen soll. Unser Ziel war klar: Der Benutzer soll möglichst wenig tun müssen. Large Language Models benötigen einen Prompt, in dem beschrieben wird, welche Aufgabe erfüllt werden soll. Es wird typischerweise zwischen Systemprompts und Userprompts unterschieden. Der Systemprompt gibt dem LLM an, unter welchen Rahmenbedingungen es operieren soll und über welche Werkzeuge es verfügt (bspw. Datenbankanbindungen). Der Userprompt ist die Eingabe vom Benutzer, der die spezifische Aufgabe beschreibt.
Generierung des Systemprompts
Schritt eins also: Wir nutzen das LLM zur Generierung des Systemprompts. Dafür bieten wir dem Nutzer verschiedene Optionen an, um den Output steuern zu können. Zunächst fiel die Wahl auf eine zwei-dimensionale Matrix:

Recht bald wollten wir aber noch mehr einstellen können, sodass weitere Slider hinzukamen, angelehnt an die “Personality Sliders” aus dem Three Hour Brand Sprint:

Zu guter Letzt noch ein wenig Chaos, denn was wäre ein Hackathon ohne ein wenig Absurdität? Unsere Vorstellung war, dass man stufenlos zwischen seriösen Texten und Lovecraft’schen Horrorbeschreibungen wechseln kann. Leider stellte sich heraus, dass sich heutige LLMs ungern dazu bewegen lassen, völlig zu entgleisen und selbst unsere kräftigsten Versuche schlugen fehl, durch Anpassungen im Prompt zum gewünschten Ziel zu gelangen.

Mit diesen Angaben wurde das LLM gefüttert, um einen Systemprompt zu schreiben, mit welchem dann die nächste LLM betrieben werden soll. So ein Systemprompt sieht dann beispielsweise so aus:
=== WRITING STYLE INSTRUCTIONS ===
## Length & Detail
Provide thorough coverage. Include explanations, context, and supporting details.
## Language Style
Lean towards expressiveness. Include some creative language and descriptive elements.
## Voice & Personality
Write for a general audience. Keep language accessible and relatable.
Lean towards playfulness. Include some light moments and engaging touches.
Be rebellious. Actively challenge norms and take contrarian positions.
Lean towards friendliness. Be personable and warm.
Somewhat fresh tone. Include some contemporary language and references.Generierung des Contents
Mit dem Systemprompt ausgestattet, können wir nun zum nächsten Schritt übergehen: Die Erzeugung des Contents selbst. In Statamic wird Content in Collections (engl. für Sammlungen) zusammengefasst, wobei die Form des Inhalts durch Blueprints (engl. für Blaupausen) vorgegeben wird. In unserem Testcase eines Zoos heisst dies: Wir haben eine Sammlung, in der die Daten für Tiere abgelegt werden. Das Blueprint eines Tieres beinhaltet Felder wie den Namen, die Ordnung, Familie und Gattung des Tieres, eine Auswahl an Lebensräumen, in der das Tier aufzufinden ist, mögliche Fressfeinde, Aktivitätszeiten und vieles mehr. Damit ist eine Vielfalt an Datentypen (Uhrzeiten, Auswahlfelder, Freitextfelder) gegeben, an denen wir die Fähigkeiten des LLMs testen können.
Dieses Blueprint muss zunächst in ein Schema verwandelt werden, welches die Datenstruktur klar definiert und ggf. weitere Informationen enthält. Beispielsweise besteht das Feld “Aktivitätsmuster” aus zwei Zeiteinträgen für “von” und “bis”. Anhand der Beschreibung des Feldes, welches wir gerne auch menschlichen Administratoren zur Orientierung zur Verfügung stellen zusammen mit dem Datentypen erschliesst sich dem LLM, welcher Inhalt bei welchem Feld erwartet wird.


Mit diesem Schema kann dann beim LLM ein structured output (engl. für strukturierte Ausgabe) angefordert werden, was bedeutet, dass das LLM ausschliesslich Ausgaben zurückgeben kann, die dieser Form entsprechen. Wie stringent sich die Ausgabe tatsächlich am Schema orientiert, unterscheidet sich jedoch zwischen den verschiedenen LLM Anbietern, sodass es generell notwendig ist, das Schema selbst nochmals nachzuvalidieren und mit fehlenden oder fehlerhaften Einträge zu rechnen.
Das LLM kann lediglich Texte produzieren. Für Bildfelder definieren wir daher im Schema, dass hier ein Prompt für ein Bild geschrieben werden soll. Dieses Prompt wird dann einer weiteren LLM übergeben, um ein passendes Bild zu generieren.
Resultat
Nun, da die Contentpipeline stand, fehlte nur noch das Frontend, um die generierten Daten auch anzuzeigen. Während wir im Backend noch (zumindest zu Beginn des Hackathons) grösstenteils selbst den Code schrieben und AI Tools lediglich im Rahmen unserer üblichen Anwendung walten liessen, hatten wir beim Frontend deutlich weniger Skrupel. Wir hielten es im Backend für wahrscheinlich, dass zumindest Teile des Codes auch ausserhalb des Hackathons in Projekten Anwendung finden könnten. Im Frontend hingegen war klar, dass jeglicher Technical Debt völlig ohne Konsequenzen ist und niemand diesen Code jemals warten oder - noch schlimmer - wiederverwenden wird.
Von daher wurden alle Bedenken über Bord geworfen und der AI völlige Freiheit gelassen, für die aus dem Backend kommenden Daten eine sinnvolle Darstellung zu erzeugen. Und dank der Verwendung von Nuxt UI als solide Komponentenlibrary lässt sich das Endergebnis sehen.
Aus einer kurzen Beschreibung der gewünschten Seite werden völlig automatisch alle benötigten Bilder und Texte passend generiert.
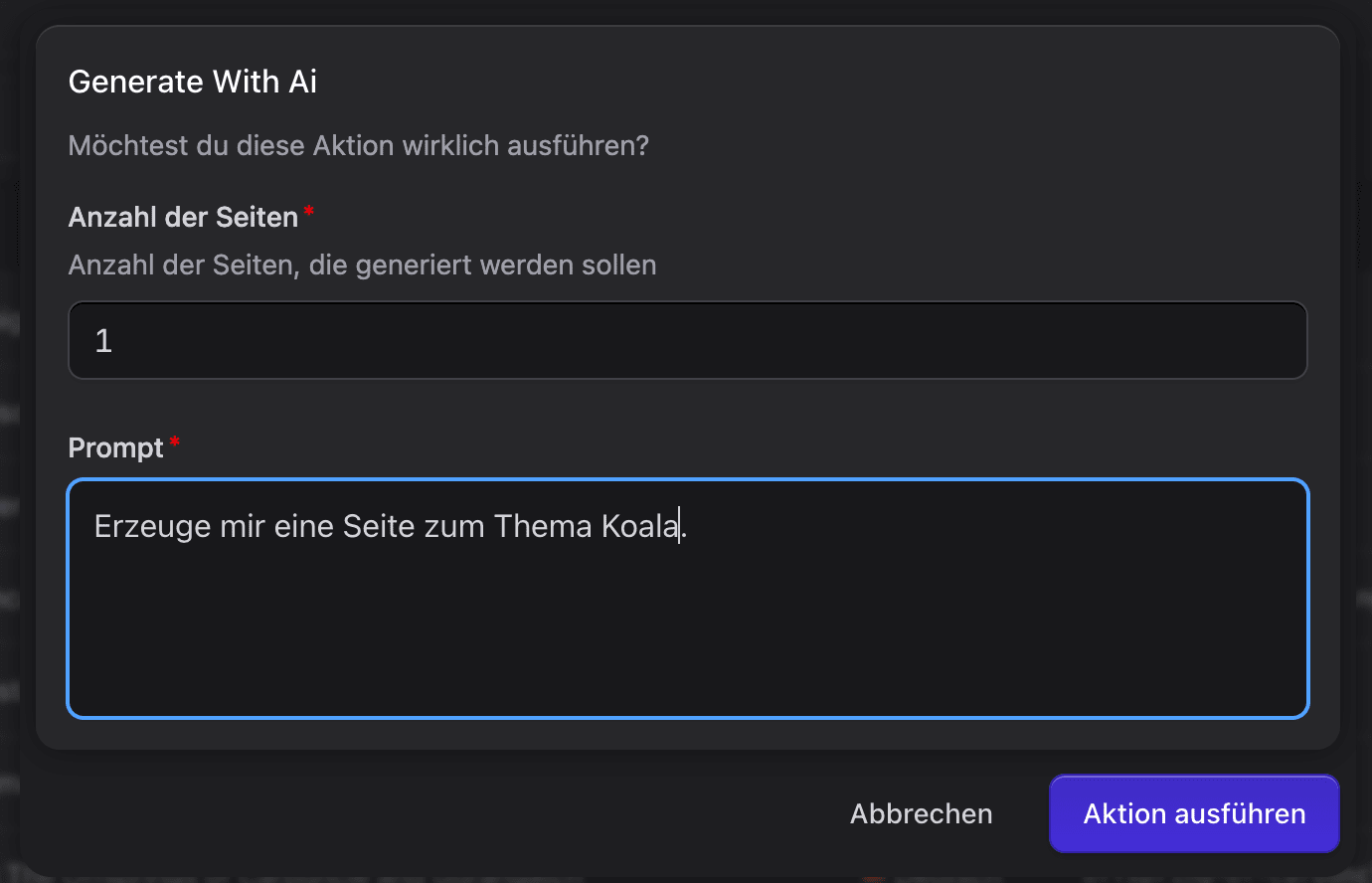

Fazit
Unser Hauptziel des Hackathons wurde erreicht: Wir hatten eine Menge Spass bei der Implementierung der AI Tools und können im Resultat die gesamte Datenstruktur durch AI voll-automatisiert abfüllen lassen. Während es für unsere Kunden nicht die Qualität und Konsistenz in den Inhalten bietet, die wir anstreben, ist es als Platzhaltergenerator für unsere Entwickler tatsächlich nützlich, um zügig eine realistische Menge Daten zum Testen von Filtern, Pagination und Ähnlichem generieren zu können.